Model Choice
In the case of linear regression, we choose as our model the class of linear functions. A linear function f(x) over m variables has a general form where is a vector in feature space, are the elements of that vector, is a vector of weights. Any function of this form, when plotted over the variables from to , will describe a plane or hyperplane.
Our goal is to find a linear function that predicts the labels based on the feature values for any point. We find a linear function that predicts the labels within our training data with high accuracy. ‘Finding’ a linear function here refers specifically to finding a set of weights that maximize accuracy or, equivalently, minimize loss, on our training set.
With no risk of confusion, we will drop the in , and write it simply as . If we concatenate a 1 to the beginning of any datapoint vector , then our linear function can be expressed as a dot product:
To take the constant terms into account, we shall restructure our feature matrix as
And We denote those biases, constant terms, as w0, and define our weight vector correspondingly as:
Given a set of weights, we can compute the linear prediction function for every point in our training set at once, with a simple matrix multiplication.
Notice the right side of the equation is a set of linear functions, given a common set of parameters applied to every point in our dataset. If all our datapoints happens to fall on a single plane, then there exists some weights with which our model will perfectly fit the data. This means that , will be equal to the true label vector y. In practice, this is never the case, the data does not fall perfectly on a linear surface, then there is no perfectly fitting set of weights.
Our training algorithm should find the “best” set of weights. We define the best set as those that minimize a cost function, given by
where n is the number of datapoints in our training dataset. The element refers to the row of our training data matrix, , and the term refers to the corresponding label for that point, which is the element in the label vector .
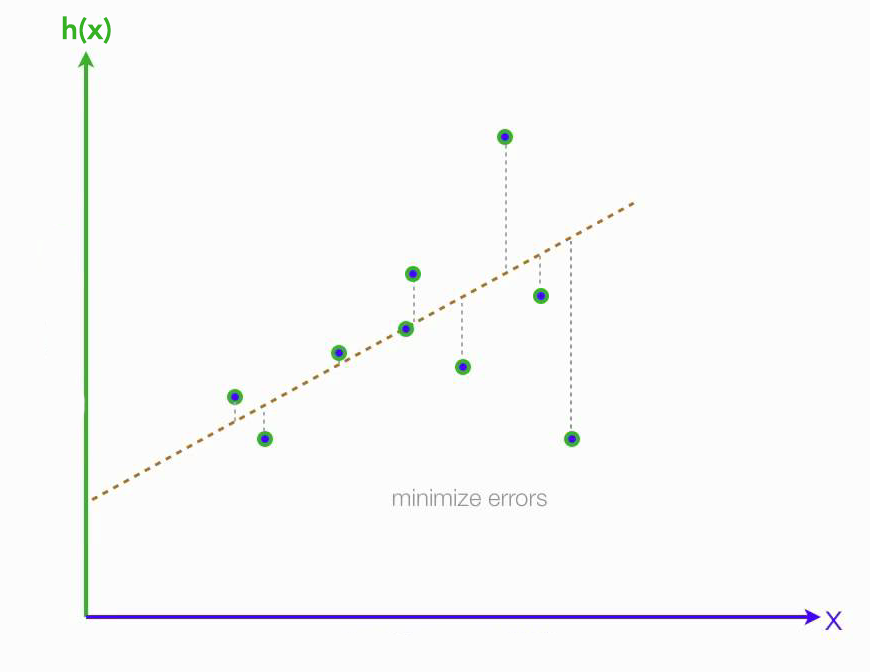
sum-squared error function
This function takes the summed distances between all the predictions for every point and their corresponding labels. In general, it shrinks as the predicted values get closer to the true labels. This is called the sum-squared error function.