Key idea: maximizing the margin
Below is a simple illustration of a binary classifier in a two-dimensional feature space. Note that the image below has two classes, red and yellow. We can find a decision boundary, as with any parametric classifier, that divides the data into two regions. The perceptron is one of the first popular algorithms that find a set of parameters in this way. A linearly separable dataset often has infinitely many viable decision boundaries. The perceptron will iteratively test potential boundaries, and then return the first decision boundary with perfect accuracy that it discovers. There is no intrinsic way to decide which of the infinite possible boundaries is best for our problem. Other AN methods like logistic regression suffer from similar problems.
The SVM training method finds the decision boundary with the widest margin. The idea is that the further a boundary from the two closest points of either class, the more robust the boundary against outliers. As a side note, there are infinitely many boundaries that share a single margin. This is a set of parallel boundaries. Implicit in the SVM definition is the fact that of the set of boundaries with the widest margin, the choose the one that is equidistant from either class. This is the central most boundary in a set of common ones.
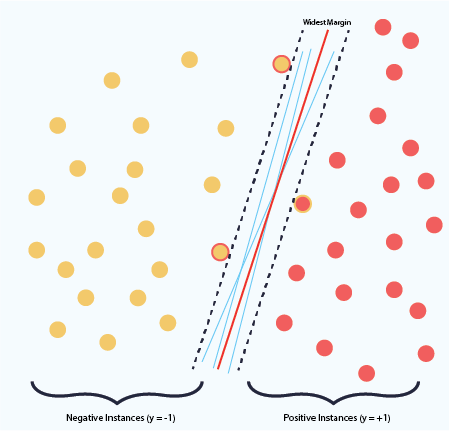
Because any new data is likely to contain noise, and we want a decision boundary that generalizes well to small permutations of the existing dataset. Because the widest margin decision boundary is the one least susceptible to noise, it is most resilient against overfitting.