Perceptron Learning Algorithm
This section explains how an ideal set of weights can be found. The process of finding some ideal parameters for our training data is called model training. For training to occur, the perceptron needs to be given a set of training points, as well as a set of corresponding labels per training point. Learning from such a set is called supervised learning, which the perceptron is the first major published case of. Let some training set be defined as a matrix X with m data points, each in n-dimensional space. Each row of X is a datapoint in some feature space. And the set of labels, ym is a vector of labels corresponding to each training point.
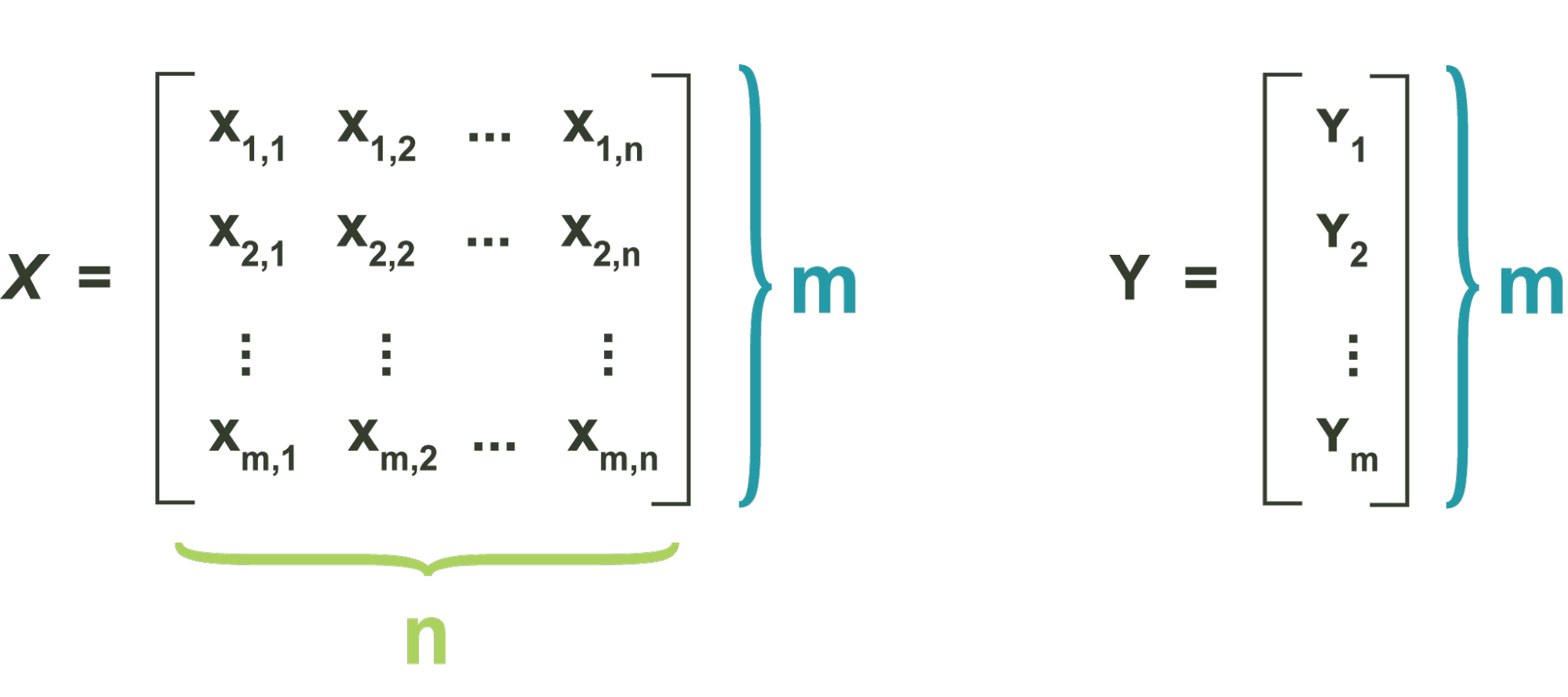
The ideal set of weights is the set that minimizes the classification accuracy on this training set. We start with a random set of weights, and then intelligently update them based on their effect on classification accuracy. This second step is performed iteratively, with the training error improving on every step. Eventually our entire training set is correctly classified, meaning that our training accuracy has gone to 100%, and we can finish training. The update rule for every iteration of our training algorithm is given in terms of the whole weight vector by Where is the old weight vector, is the new weight value we’re updating to, η is a user-defined constant called the step size, is the true label for some point , is the output of the perceptron for that same point, using the previous weights, . The perceptron learning algorithm is performed via the following steps:
