Dual Language formulation for kernels
Recall that the dual problem for classic SVM is to maximize the following function over
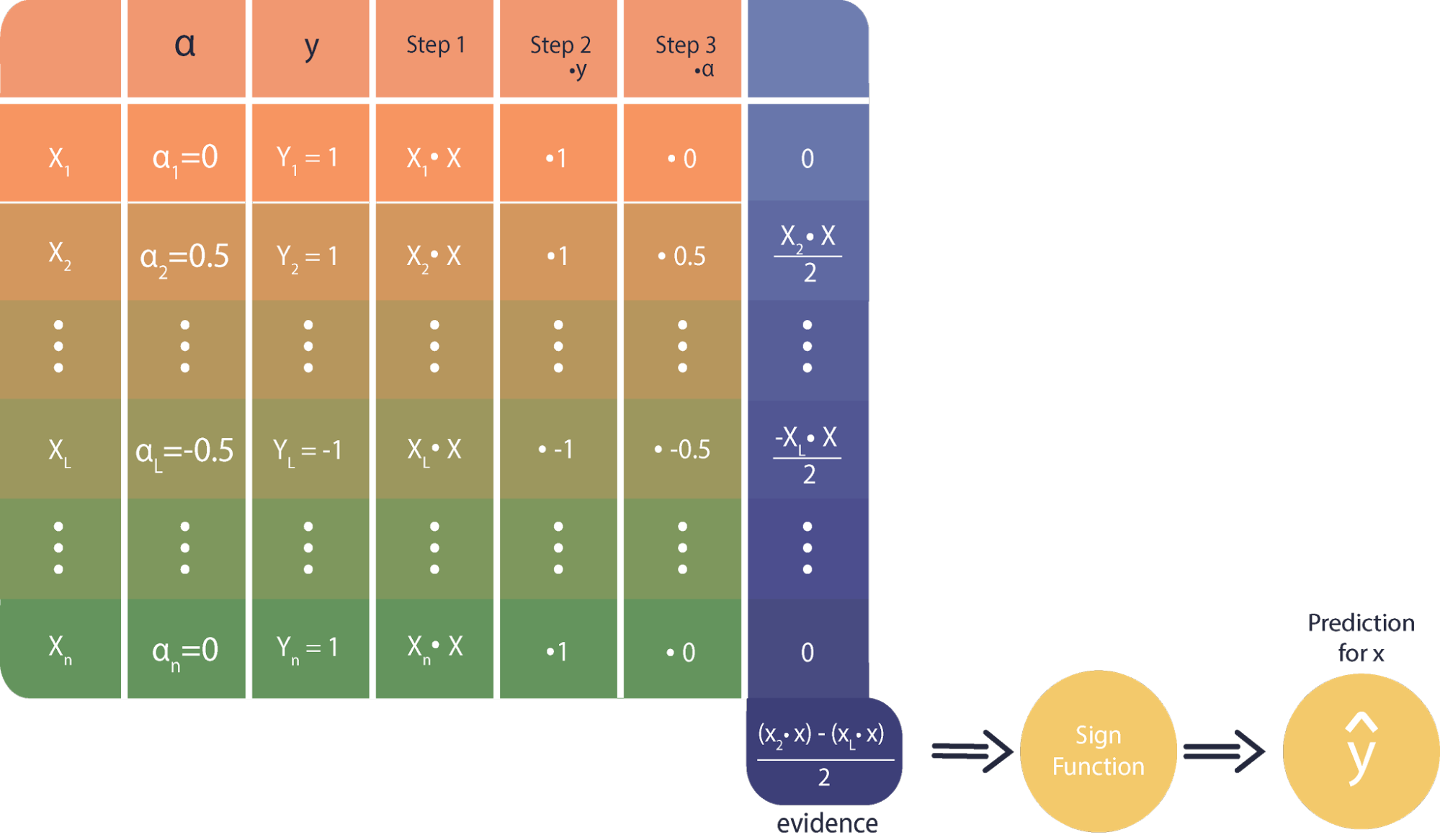
Notice that both the training form, as well as the classification form, are written in terms of dot products between vectors. These dot products need to be understood as similarity functions between these points. The logic of the classifier is that a set of vectors, called the support vectors, are compared against a new point to be classified. The resulting similarity values are combined with the class and importance value of the support vectors. These combined values are summed; the sign of this sum determines the predicted class of the point.
Subject to ,
For kernel SVM, with each mapped to some higher dimensional vector , the equation becomes
with the optimal weights given by
and the optimal plane given by
and the optimal decision function given by
The explicit coordinates in the higher dimensional mapping space, and even the mapping function become unnecessary when we define a function , the so called kernel function, which directly calculates the value of the dot product of the mapped data points in some feature space. We can avoid explicitly computing for any point, or handling the dot product of points in space. The only drawback here is that we have to use some well defined function that we know corresponds to some useful feature transformation .
Thus, using Kernel function, we can write the equation of dual formulation as
.