Common kernels
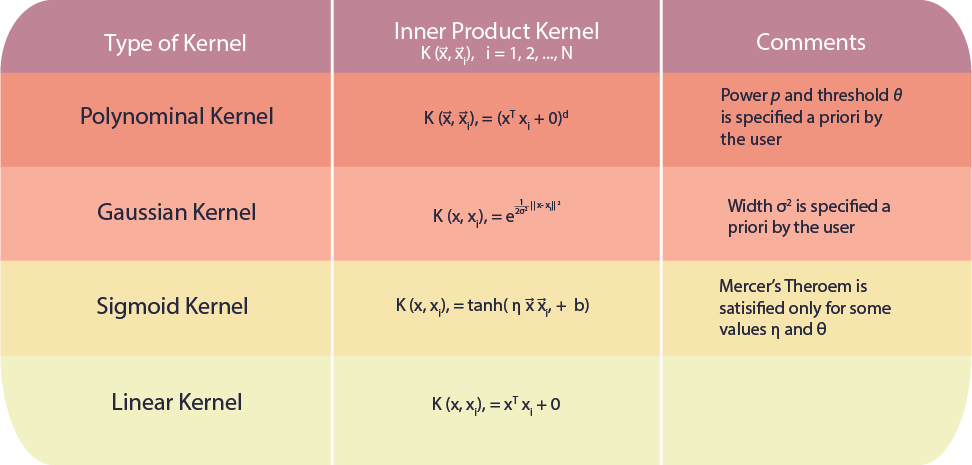
Summary of Inner-Product Kernels
The above table shows some common kernels. Although some kernels are domain specific there is in general no best choice. Since each kernel has some degree of variability in practise there is nothing else for it but to experiment with different kernels and adjust their parameters via model search to minimize the error on a test set. Generally, a low polynomial kernel or a Gaussian kernel have shown to be a good initial try and to outperform conventional classifiers.
Polynomial Kernel
In this section we show that using polynomials as a basis can also be computed using a kernel. This is an example of how the kernel can be easier to compute, instead of computing the expansion into all possible polynomial terms. We could model the introduction of polynomial terms as a function from vectors x to vectors in a higher dimensional space where p is the order of our polynomial. If we replace each row of X (examples in the data) with , note that in the dual, we would have a matrix of inner products . It turns out that for certain values of the expansion, we can compute the dot products directly, instead using a kernel function. For , the polynomial kernel is: note that we can rearrange terms since $x^{T}x$ is a scalar: Which is the same thing as
Gaussian Kernel
This is the most widely used kernel. This kernel measures similarity as
and there are a few ways to think of this kernel. One is as a radial basis function neural network, with fixed weights: it centers one basis function at every training data point.
Often in the literature it's referred to as a projection into infinite-dimensional space. The basic argument is that the kernel matrix extracted will always be full rank, so that you can always incorporate additional points. Recall that a full-rank kernel is positive definite.
Another explanation is that the points are lifted to a hypersphere, or actually nonnegative orthant of a unit hypersphere. The maximum of the Gaussian kernel occurs when we measure the distance between a point and itself, where the expression evaluates to . This means the length of each data point is , placing it on the sphere. Distances are going to be bounded between and , because they cannot be negative. This also ensures that the kernel has to be positive definite.
The gaussian kernel contains all functions, because it is full rank. It contains all linear decision boundaries It contains all polynomials, for example if you were doing regression, using the gaussian kernel would give you a polynomial shaped prediction. It contains the constant function, which means that the bias term is unnecessary.
Random Kitchen Sinks
Kernel methods don’t scale well beyond a few thousand points, because the main computational work is inverting the kernel matrix, which grows with the number of points. However, we might want to train a nonlinear method like a support vector machine on millions of points. We have seen in the support vector machine that a linear support vector machine can be trained very quickly using an algorithm like PEGASOS.
This suggests the following idea: use a large number of fixed, but random features. Random features multiply the input datapoint by a random weight vector, then threshold based on the sign. This is the same thing as using a randomly wired neural network, without learning, and this method is very old, for example appearing in the very first paper on perceptrons in 1958. The surprising things are that 1) it works very well in practice (and theory) and 2) with careful attention to the choice of random distribution, you can approximate kernels such as the Gaussian Kernel.
An example is shown below. The data points form two different classes, and , and we can see in the figure that a nonlinear decision boundary is necessary. The colors plot the decision surface: recall that the prediction rule is thresholding the dotproduct to give class or . Points which are more red are in one class, points in blue are in the other class. The figure below used the gaussian kernel:
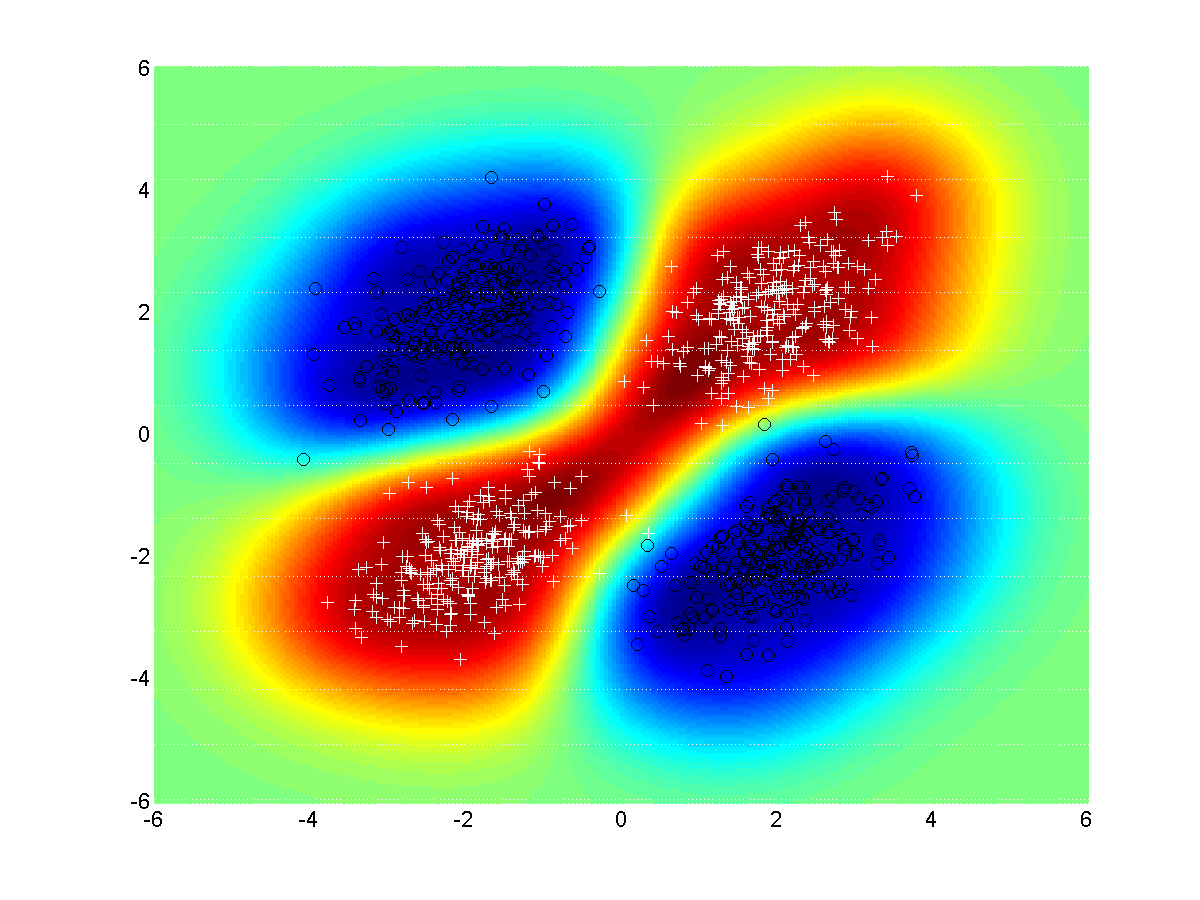
In the next figure, we plot the same decision boundary, but now using a randomly wired input layer (random kitchen sink features). Although not as smooth, this network can still solve the XOR problem.