Choosing K as a Hyper-Parameter
The nearest neighbor algorithm is very sensitive to noise. The choice of ideal K is extremely important, and produces drastic differences in performance. Typically an odd-numbered K is chosen to avoid ties. If the K is very small, then the algorithm is extremely sensitive to noise and outliers. When the K is too large, then the system is biased towards the most common class in the training set, all will be more likely to return the same value for all points.
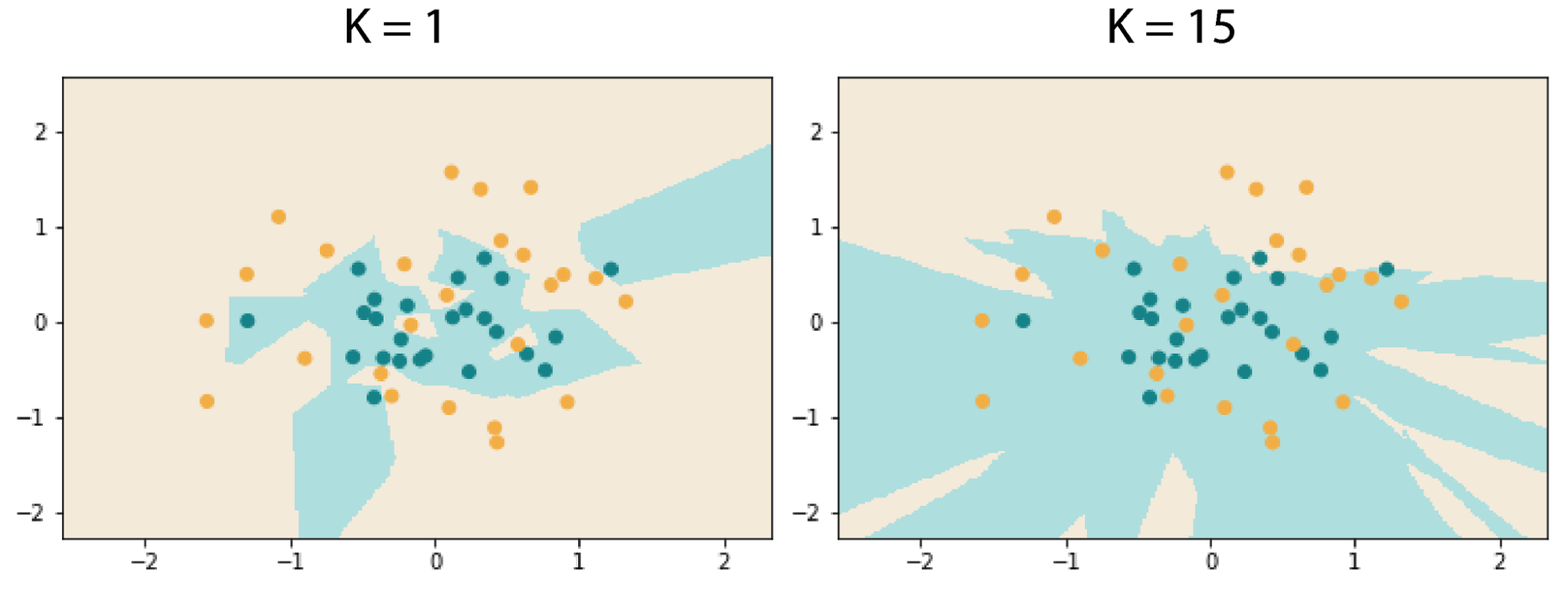
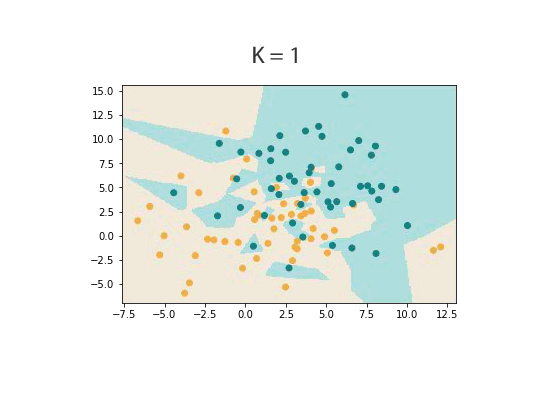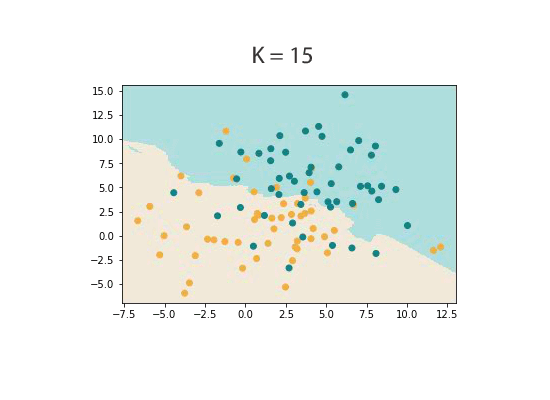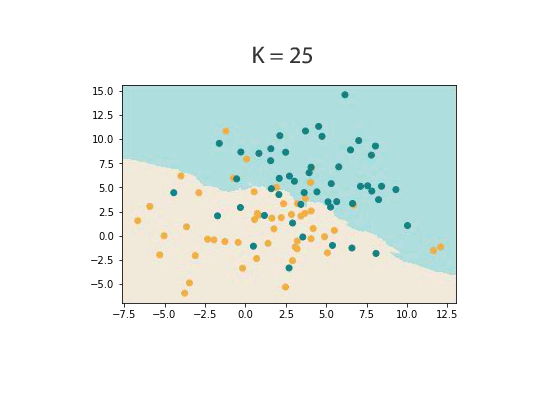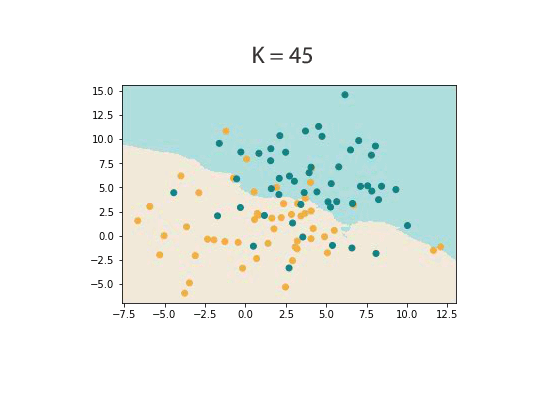
Below is an illustration of the effects on classification boundaries between different choices of K. Notice the smoother boundary in the right case.
K is usually chosen by using a validation set. A validation set is just some portion of the labelled dataset that has not been used in training stage. Because training on a data set in KNN is just storing that set, a validation set is just a portion of the data that isn’t ‘seen’ by the classifier.
We decide of the best K according to the elbow rule. We test on the validation set many times, storing the accuracy at every run, and vary the value of K across those runs. We then plot the validation accuracies as a function of K. The elbow rule refers to the fact that there will be a point of diminishing returns on the set, which well resemble a joint on a line plot; the highest value of K before this joint is the ideal K.
Let’s consider the following case. We have a dataset that we want to select an ideal K value for. We decide to withhold a random minority of that data, which we will call the validation set. We choose a value of K, and then train the KNN classifier on the remaining dataset, then classify and score the validation set. We save this score, and repeat the process for several reasonable values of K. We can chart the performance of this measure as a function over K as follows.

In this example, we would choose a K of 7.
This simple method is called validation, or more precisely naive validation. There are other, more complex varieties like cross-validation and leave-one-out cross validation
The choice of K is extremely important, and is almost always the most involved aspect of training a KNN classifier. The need to choose a K, and the cost that this incurs is the trade-off for the simplicity and effectiveness of KNN.